One of the little tools in my back catalogue that I thought it may be useful to share is for the purpose of parsing a 7Bit PDU file found on some of the cheaper LG Flip Phones (A448 I'm looking at you...) Despite being a "dumb phone" I've found surprisingly few tools are able to parse this data, or at least I did a couple of years ago when I wrote this. I do believe that Final Data are able to parse these records, but at the time my agency wouldn't commit to buying yet another tool and so I set to work on making this.
I have also found that this kind of encoding is overlooked or easily forgotten about. My own time at the Canadian Police College saw it mentioned only very briefly and I have it on good authority that things haven't changed in the last few years. Many examiners who have heard of it still don't really know what it is, how it works or why it's used. This blog post will hopefully answer those questions.
During my further work in order to write this blog post and update the tool to make it a little more intuitive, I also had the opportunity to revisit some of the bits that didn't work as well as they could. I have given this tool to a number of people over the last couple of years and if that includes you, I'd recommend redownloading to take advantage of the updates.
PDU stands for "Protocol Description Unit" which is not overly helpful when trying to understand what it is. But if you can think back to sending messages from non-smart phones, you may recall there was a limit to the number of characters you could send via SMS. Even now, that limit still applies, although it's somewhat obsfuscated by multipart messages and by services (such as iMessage) or MMS.
The limit on the size of SMS is due to the maximum size that could be managed by the SMS network. This limit typically mean a maximum length of 140 bytes for the actual message and additional bytes used for destination, service centre number, sender, timestamp etc.. These messages were sent using a modified ASCII alphabet, where a single character requires 8 bits. Since 8 bits equals 1 byte, then 140 bytes means 140 characters maximum for the message.
As I'm sure everyone is aware, 8 bits are capable of displaying every number between 0 and 255 which is somewhere around double the number of characters in the GSM Alphabet table:
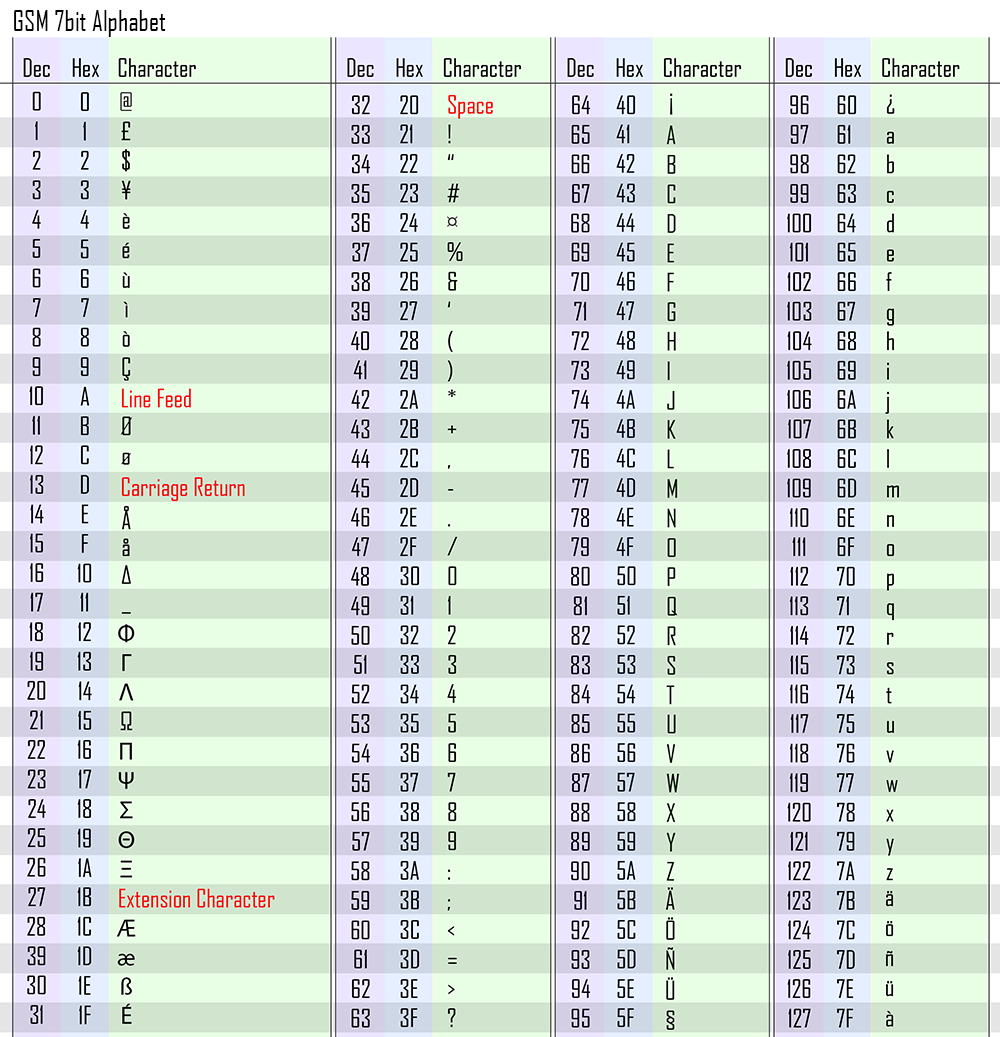
Although the difference between 127 and 255 amounts to a difference of 128 numerical values, in binary, they all are the same in that their first bit is always 1. That is to say that every number 128 and above has the first bit of the byte to be a 1 and every number 127 and below has the first bit of the byte as a 0.
On these phones that only support standard ASCII, no value above 127 is ever required. And yet, because a byte is 8 bits, that first bit is being sent on every message even though it's a 0 every single time. What a waste!
7Bit PDU (aka GSM-7) is a way to utilize that bit, effectively making each byte only 7 bits instead of 8. Therefore you can send 9 bytes worth of data by using only 8 bytes.
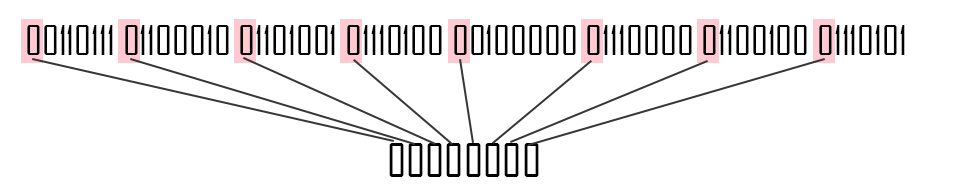
OK. So this is a terrible example as this is nothing like how it works. But it somewhat illustrates the point.
The result of this technique is that using the same 140 bytes that we had originally, we can now effectively transmit an additional 20 characters, giving us a total of 160 characters instead of 140. It may not sound like much, but it's an increase of almost 15%.
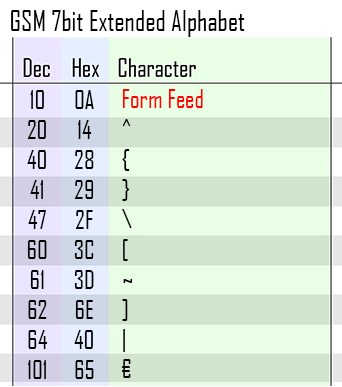
Remember how I said that there was only 128 characters in the GSM characterset? Well thats not entirely true. You may have noticed on the table above that 0x27 is "Extension Character". What that means is that there are a small number of additional characters that fall outside of the chart shown above and have to be called by using the 0x27 escape first.
In order to do this, the alphabet reuses numbers that have already been assigned. In the extended charset, 10, 20 and 40 are reused for example. So where ordinarily 0x40 is a "(" character, when it is preceeded by a 0x27 then it becomes a "{". The other extension characters include:
To begin encoding a Message Body, we need to reduce each individual byte (which is 8 Bits, or Octets) into 7 Bits (Septets). This is really easy to do because we already know that by using the limited GSM alphabet that we are limited to in these messages, we never need use the first bit anyway. So we can simply throw it away!
| ASCIII |
D |
o |
u |
b |
l |
e |
B |
l |
a |
k |
| Hex |
44 |
6F |
75 |
62 |
6C |
65 |
42 |
6C |
61 |
6B |
| Octet |
0100 0100 |
0110 1111 |
0111 0101 |
0110 0010 |
0110 1100 |
0110 0101 |
0100 0010 |
0110 1100 |
0110 0001 |
0110 1011 |
| Septet |
100 0100 |
110 1111 |
111 0101 |
110 0010 |
110 1100 |
110 0101 |
100 0010 |
110 1100 |
110 0001 |
110 1011 |
Note that the additional conversion from ASCII to Hex is purely illustrative and is not required to make this work.
Wahey! All your 'bytes' are now 7 bit!
But leaving it there would be way too easy. :)
Next, starting at the first septet, we need to take the least significant bit(s) from next septet and place it at the start of the current septet.
So starting at Septet 1, take the last bit from Septet 2 and place at the start of Septet 1, making it into an Octet again, but leaving septet 2 as a sextet (6 bits).
Then take two bits from Septet 3 and place them at the start of Septet 2, making Septet 2 a Octet and leaving Septet 3 as a quintet (5 bits).
Take 3 bits from Septet 3 and place at the start of Septet 2. And so on... like this...
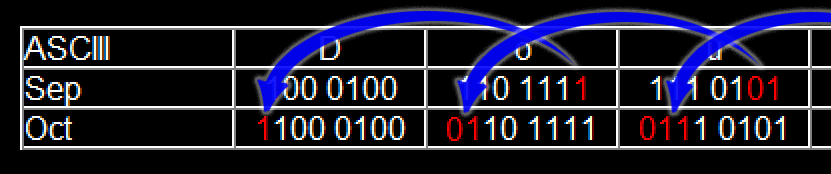
Keep on with this pattern and by the time you get to the 7th byte, you'll see that there isn't an eighth septet anymore. Septet 9 simply starts the whole process again.
The very last septet of the message is then padded with 0's to bring it back to being an octet again (Shown in Yellow).
The entire table will then look like this...
| ASCIII |
D |
o |
u |
b |
l |
e |
B |
l |
a |
k |
| Hex |
44 |
6F |
75 |
62 |
6C |
65 |
42 |
6C |
61 |
6B |
| Octet |
0100 0100 |
0110 1111 |
0111 0101 |
0110 0010 |
0110 1100 |
0110 0101 |
0100 0010 |
0110 1100 |
0110 0001 |
0110 1011 |
| Septet |
100 0100 |
110 1111 |
111 0101 |
110 0010 |
110 1100 |
110 0101 |
100 0010 |
110 1100 |
110 0001 |
110 1011 |
| Octet |
1100 0100 |
01110 111 |
010111 01 |
1100 1100 |
0010 1110 |
0000 1011 |
1101 1001 |
NOT USED |
1110 0001 |
0011 0101 |
Finally, convert your newly constructed octets back into Hex.
| ASCIII |
D |
o |
u |
b |
l |
e |
B |
l |
a |
k |
| Hex |
44 |
6F |
75 |
62 |
6C |
65 |
42 |
6C |
61 |
6B |
| Octet |
0100 0100 |
0110 1111 |
0111 0101 |
0110 0010 |
0110 1100 |
0110 0101 |
0100 0010 |
0110 1100 |
0110 0001 |
0110 1011 |
| Septet |
100 0100 |
110 1111 |
111 0101 |
110 0010 |
110 1100 |
110 0101 |
100 0010 |
110 1100 |
110 0001 |
110 1011 |
| Octet |
1100 0100 |
01110 111 |
010111 01 |
1100 1100 |
0010 1110 |
0000 1011 |
1101 1001 |
NOT USED |
1110 0001 |
0011 0101 |
| Hex |
C4 |
77 |
5D |
CC |
2E |
0B |
D9 |
NOT USED |
E1 |
35 |
So there you have it. The 10 bytes you would usually need for "DoubleBlak" (44 6F 75 62 6C 65 42 6C 61 6B) have been shrunk down to the svelt 9 bytes of C4 77 5D CC 2E 0B D9 E1 35 by using PDU.
OK, I know it doesn't sound too impressive, but back in the early 2000's this would have been massive. And for the phones that still support it, it's certainly good to understand.
Here, you can have a little play with it and see in real time the conversion the text goes through.
| Plain Text |
|
| Hex |
|
| Binary (Octets) |
|
| Binary (Septets) |
|
| PDU (Binary) |
|
| PDU (Hex) |
|
| Savings by using PDU |
|
*Again, the conversion from Plain Text to Hex isn't necessary but is nice to see.
So now you know how to encode the User Message from plain ol' ASCII into 7-bit PDU. Now you have to be able to decode the message once recieved by the recipient. Luckily, the decoding process is the exact reverse of the encoding process.
So take the Hex and convert it to Binary. Now we need to remove the Most Significant Bits and append then back onto their original byte.
So starting at Byte 1, remove the most significant bit and append it to the end of Byte 2, leaving Byte 1 as 7 bytes.
At byte 2 (which is now 9 bytes long) remove the first 2 bytes and append them to the end of Byte 3.
At Byte 3 remove the first 3 bytes and append them to the end of Byte 4. And so on. This results in each of the "bytes" being only 7 bits long with the exception of "Byte" 7 which will actually be 14 bits long now. Simply split this down the middle and pad both halves with a 0 at the start to bring them both back to octets.
Finally, convert the bytes back into the GSM CharSet to see the original message.
Here's another handy little decoder toy that allows you to enter the PDU Hex from above and decode it back into readable text.
| PDU (Hex) |
|
| PDU (Binary) |
|
| Binary (Septets) |
|
| Binary (Octets) |
|
| Resulting Hex |
|
| Plain Text |
|
The Message Body isn't th only thing you need to understand however. And now you're pretty much an expert at encoding and decoding the PDU Messages we need to cover off how to use it in an actual message; the entire message also needs to include recipient, sender, SMSC, timestamp information etc.
We'll start with Receiving Messages;
The structure of a received PDU Message changes, and is defined by itself. So for example, the first byte defines the length of the SMSC number. This means that I cannot give you a neatly organised table with offset numbers for each item, because those offsets change.
What I can do, is show you the order of the message parts, what they are and how to decode them.

Above shows a Received SMS message from an LG A448 in the GSM-7 (7 bit PDU) format. As you can see from the ASCII at the right, there are no identifiable characters legible.
The colour coding I have applied infers:
| Colour |
Description |
| Dark Green |
Length of the SMSC (SMS Centre) Number.
This defines the number of digits there are in the SMSC number. (Note this is digits, NOT bytes)
In this case, x0B = 11 digits.
*Note that this field may not be present on the device itself. |
| Not Shown |
Type of SMSC Address
The only bits we really care about of this byte are bits 1,2 and 3 (0 indexed) as these refer to:
| Type of Number |
| 000 |
Unknown |
| 001 |
International |
| 011 |
Network Specific |
| 100 |
Subscriber |
| 101 |
AlphaNumeric |
| 110 |
Abbreiviated |
| 111 |
Reserved |
*Note that this field may not be present on the device itself. |
| Brown |
SMSC Number
I have seen the SMSC displayed in two different fashions; either as is depicted in the example image above:
-To convert, simply ignore the leading 0 on each byte. So 01 06 01 03 becomes 1613 and so on.
OR
Decimal Semi-Octets:
-To convert, swap the nibbles around, so 61 becomes 16 and 31 becomes 13 and so on. Note that there may be an F at the end is padding round up to an even number. You can just ignore it.
*Note that this field may not be present on the device itself. |
| Dark Grey |
Undefined
These bytes are not covered by the SMS Specification as far as I can see. It appears to only be relevent to the kind of device this image is from. I would therefore say it is safe to ignore. In my case, every message had the same 13 bytes. |
| Light Grey |
First octet of the message
This single byte defines several things about this message that the SMS Network needs to know. They are mostly not so important for forensicators and to go into this data further is outside the scope of this blog post. If you are interested in further reading, try this.
The byte breaks down as:
| First Octet |
| Bits |
Name |
| 0 |
TP-Reply-Path (TP-RP) |
| 1 |
TP-User-Data-Header-Indicator (TP-UDHI) |
| 2 |
TP-Status-Report-Request (TP-SRR) |
| 3&4 |
TP-Validity-Period-Format (TP-VPF) |
| 5 |
TP-Reject-Duplicates (TP-RD) |
| 6&7 |
TP-Message-Type-Indicator (TP-MTI) |
In terms of Received Messages, the only bits we care about are 6&7 which define this message as a Received Message by being x00. If they were x01 then this would be a Sent Message.
There are actually several variations that deal with Service Messages or Read Reciepts etc but I won't cover those here. |
| Pink |
Length of the sender address (ie sender phone number)
0A = 10 digits. This is a little tricker than the SMSC number because the number is somewhat encoded. So this time, a 10 digit phone number doesn't mean that we need 10 bytes. We actually need half this number.The reason why will be explained later.
|
| Yellow |
Type of Sender Address
The only bits we really care about of this byte are bits 1,2 and 3 (0 indexed).
| Type of Number |
| 000 |
Unknown |
| 001 |
International |
| 011 |
Network Specific |
| 100 |
Subscriber |
| 101 |
AlphaNumeric |
| 110 |
Abbreiviated |
| 111 |
Reserved |
|
| Violet |
Sender Address (Phone Number)
This number is saved in "Swapped Nibble Mode" which is to say it is basically just jumbled up.
We already know the length as it was defined 2 bytes ago as being 10 digits long. However we only need 5 bytes because each byte contains 2 digits.
For each of the bytes, simply swap the nibbles around, so 04 becomes 40, 63 becomes 36 etc.
| Original |
21 |
43 |
65 |
87 |
90 |
| Swapped |
12 |
34 |
56 |
78 |
09 |
So the sender number is 123 456 8790.
Note that if there is an F present in the string, it is just padding and can be ignored. |
| Red |
TP-PID (Protocol Identifier) |
| Dark Orange |
TP-DCS (Data Coding Scheme)
This is the type of encoding used for the message. Of most relevance (to this article anyway) is if this octet is under 4 then 7bit PDU is in use.
More information on the Data Coding Scheme can be found here. |
| Light Green |
TP-SCTS (Time Stamp in Semi-Octets)
The TimeStamp field is recorded in 7 bytes; 1 byte each for Year, Month, Day, Hour, Minute, Second and TimeZone.
As with the Sender number, the date is recorded in "Swapped Nibble Mode" meaning the nibbles need swapping around to make sense of the value.
| Original |
10 |
21 |
13 |
| Swapped |
01 |
12 |
31 |
So the value 51 21 31 51 52 33 would be 15 12 13 15 25 53... Or 2015/12/13 15:25:35.
The 7th byte is the Timezone and this is equally as different to decode.
Let's take the timezone 0x8A. First, we need to nibble flip it to get xA8 and then display it as binary : xA8 = 1010 1000.
The first bit defines if we are dealing with UTC+ or UTC-.
x0 =
UTC+
x1 =
UTC-
In our case, the first bit is 1 so we know we are working with a UTC- offset. We are then left with the 7 bits 010 1000.
We take the remaining 7 bits and display them as Hex. 010 1000 = 0x28 but we then have to treat the resulting Hex number as if it was Decimal and divide it into quarter hours : 28 / 4 = 7
So our offset is UTC-7.
Another example would be 2B = B2 = 1011 0010 = UTC- | 011 0010 = 0x32 = 32 / 4 = 8 = UTC-8. |
| Blue |
TP-UDL (User Data Length)
This defines the number of units required for the user's message. The unit itself (whether Septet or Octet) is defined in the Data Coding Scheme above.
Presuming that we are working in 7bit PDU (since that is the focus of this article) I will explain that the user data length is shown in number of Septets, not the number of octets. So for example, if the User Data Length is x99, that means the message is 153 Septets NOT 153 Octets. If we simply took the next 153 bytes our decoded message will include some garbled text at the end because the number of bytes is wrong.
The easiest way I have found to deal with this (And I'm no mathmagician so I'm sure there is a better way) is to perform a couple of simple calculations.
| First, take the hex and convert to decimal. |
x99 = 153 |
| Then multiply by the number of bits in a Septet |
153 * 7 = 1071 |
| Then divide that number by the number of bits in an Octet |
1071 / 8 = 133.87 |
| Round up to a whole number |
134 |
| There is your answer in Octets. |
134 |
So we actually need to take the next 134 octets as this is the equivalent of taking 153 Septets. |
| Orange |
TP-UD (User Data)
We already know the length (in Octet bytes) that this message is, and we already know how to parse the data if it is in 7bit PDU. If it is not in 7bt PDU, the TP-DCS would have told us so and there would probably be some legible text here.
I'll also breifly mention in here that Multi-Part SMS Messages (where a phone splits up a large message automatically and presents it to both sender and recipient as a single message) is defined here. Without going into too much detail, a header is placed within the user data area letting the phone know that this message is part 1 of 3 for example. The header takes up 5 bytes of the User Data area. |
The first few parts of the Sent PDU Message are the same as the Received Message. The message itself is modified once received by the SMSC to convert it from a Sent Message to a Received Message. It is at that time that the TimeStamp value is added. The TimeStamp is the time according to the SMSC so should always be correct regardless of how the sending device is configured.
This is an example of an Outgoing Message in PDU format.

| Color |
Description |
| Dark Green |
Length of the SMSC (SMS Centre) Number.
This defines the number of digits there are in the SMSC number. (Note Digits NOT bytes).
In this case, x0B = 11 digits.
*Note that this field may not be present on the device itself. |
| Brown |
SMSC Number
I have seen the SMSC displayed in two different fashions; either as is depicted above:
-To convert, simply ignore the leading 0 on each byte. So 01 06 01 03 becomes 1613 and so on.
OR
Decimal Semi-Octets:
-To convert, swap the nibbles around, so 61 31 becomes 16 13 and so on. Note that there may be an F at the end to round things up, just ignore it.
*Note that this field may not be present on the device itself. |
| Dark Grey |
Undefined
These bytes are not covered by the SMS Specification as far as I can see. It appears to only be relevent to the kind of device this image is from. I would therefore say it is safe to ignore.
In my case, every message had the same 13 bytes. |
| Light Grey |
First octet of the message
This single byte defines several things about this message that the SMS Network needs to know. They are mostly not so important for forensicators to know and to go into this data further is outside the scope of this blog post. If you are interested in further reading, try this.
The byte break down is:
| First Octet |
| Bits |
Name |
| 0 |
TP-Reply-Path (TP-RP) |
| 1 |
TP-User-Data-Header-Indicator (TP-UDHI) |
| 2 |
TP-Status-Report-Request (TP-SRR) |
| 3&4 |
TP-Validity-Period-Format (TP-VPF) |
| 5 |
TP-Reject-Duplicates (TP-RD) |
| 6&7 |
TP-Message-Type-Indicator (TP-MTI) |
In terms of Sent Messages, the only bits we care about are 3&4 and 6&7 which define the Validity format and that this message as a Sent Message respectively.
| Validity Format |
| 00 |
Not Specified |
| 10 |
Relative Validity Period |
| 11 |
Absolute Validity Time |
The Message Type being x01 shows this to be a Sent Message. If it was x00 then it would be a Received Message.
There are actually several variations that deal with Service Messages or Read Reciepts etc but I won't cover those here. |
| Pink |
Length of the Recipient address (ie Recipient phone number)
0B = 11 digits. This is a little tricker than the SMSC number because the number is somewhat encoded. So this time, a 11 digit phone number doesn't mean that we need 11 bytes. We actually need around half this number.The reason why will be explained later.
|
| Yellow |
Type of Sender Address
The only bits we really care about of this byte are bits 1,2 and 3 (0 indexed).
| Type of Number |
| 000 |
Unknown |
| 001 |
International |
| 011 |
Network Specific |
| 100 |
Subscriber |
| 101 |
AlphaNumeric |
| 110 |
Abbreiviated |
| 111 |
Reserved |
|
| Violet |
Recipient Address (Phone Number)
This number is saved in "Swapped Nibble Mode" which is to say it is basically just jumbled up.
We already know the length as it was defined 2 bytes ago as being 10 digits long. However we only need 5 bytes because each byte contains 2 digits.
For each of the bytes, simply swap the nibbles around, so 04 becomes 40, 63 becomes 36 etc.
| Original |
21 |
43 |
65 |
87 |
90 |
| Swapped |
12 |
34 |
56 |
78 |
09 |
So the destination number is 123 456 8790.
Note that if there is an F present in the string, it is just padding and can be ignored. |
| Red |
TP-PID (Protocol Identifier) |
| Dark Orange |
TP-DCS (Data Coding Scheme)
This is the type of encoding used for the message. Of most relevance (to this article anyway) is if this value is under 4 then 7bit PDU is in use.
More information on the Data Coding Scheme can be found here. |
| Light Green |
TP-Validity-Period
This defines how long the SMSC should keep trying to send the message before eventually giving up. It is an optional field and may just be 0x00 which allows the cell provider to specifiy.
The format for how this information is given is provided in bytes 3&4 of the first octet.
It may be presented as a Relative Time in minutes, days or weeks (Relative to the SMSC Receiving the message), in which case:
| Decimal Value |
Description |
| 0-143 |
(Value + 1) * 5 minutes (Maximum 12 Hours / 720 minutes)
So a decimal value of 20 would be:
(20 + 1) * 5 minutes = 105 minutes
|
| 144-167 |
12 Hours + (Value - 143) * 30 minutes.
So a decimal value of 150 would be:
720 + (150 - 143) = 930 minutes |
| 168-196 |
(Value - 166) * 1 Day
So a decimal value of 170 would be:
(170 - 166) * 1 Day = 4 Days |
| 197-255 |
(Value - 192) * 1 Week
So a decimal value of 200 would be:
(200 - 192) * 1 Week = 8 Weeks |
Or it may be presented as an Absolute timestamp, where an actual timestamp is given in decimal semi-octets as described above.
*Note that this field may not be present on the device itself.
|
| Blue |
TP-UDL (User Data Length)
This defines the number of units required for the user's message. The unit itself is defined in the Data Coding Scheme above.
Presuming that we are working in 7bit PDU (since that is the focus of this article) I will explain that the user data length is shown in number of Septets, not the number of octets. So for example, if the User Data Length is x99, that means the message is 153 Septets NOT 153 Octets. If we simply took the next 153 bytes our decoded message will include some garbled text at the end because the number of bytes is wrong.
The easiest way I have found to deal with this (And I'm no mathmagician so I'm sure there is a better way) is to perform a couple of simple calculations.
| First, take the hex and convert to decimal. |
x99 = 153 |
| Then multiply by the number of bits in a Septet |
153 * 7 = 1071 |
| Then divide that number by the number of bits in an Octet |
1071 / 8 = 133.87 |
| Round up to a whole number |
134 |
| There is your answer in Octets. |
134 |
So we actually need to take the next 134 bytes as this is the equivalent of taking 153 Septets. |
| Orange |
TP-UD (User Data)
We already know the length (in Octet bytes) that this message is, and we already know how to parse the data if it is in 7bit PDU. If it is not in 7bt PDU, the TP-DCS would have told us so and there would probably be some legible text here.
I'll also breifly mention in here that Multi-Part SMS Messages (where a phone splits up a large message automatically and presents it to both sender and recipient as a single message) is defined here. Without going into too much detail, a header is placed within the user data area letting the phone know that this message is part 1 of 3 for example. The header takes up 5 bytes of the User Data area. |
Thank you for reading! I realise this is an old topic, but 7Bit PDU is still around and my parser is just as useful now as it was when it was first written. I also see great benefit in knowing what our forensics tools are doing under the hood and recognizing options when those same tools fail to find any data.
Plus, it's nice to write about something other than iOS for a change. :)
Remember, you can download my 7Bit PDU Decoder for LG Phones (for RecMngr.bin) for FREE from the 'Software' section of my site. I admit I have not tested it with any other files as I've yet to come across another phone not supported by one of our tools. If your stuck, by all means contact me and I'll see if I can make the appropriate changes.
| |